Table des matières
- 1. Qu'est-ce que la norme L1 ?
- 2. Exemple pratique de calcul
- 3. Implémentation Python : du code à la pratique
- 4. La géométrie de la norme L1 et la sparsité
- 5. Pourquoi "norme de Manhattan" ?
- 6. Applications en Machine Learning
- 7. Cas d'usage : un modèle prédictif épuré
- 8. En résumé
Pour calculer facilement une norme L1 en programmation, on utilise couramment la bibliothèque NumPy en Python avec la logique suivante :
import numpy as np
x = np.array([x1, x2, x3, x4])
norme_L1 = np.sum(np.abs(x))La sortie est tout simplement la somme stricte des valeurs absolues des éléments de votre tableau !
1. Qu'est-ce que la norme L1 ?
1.1. Définition mathématique
En mathématiques, une norme est une fonction qui permet d'évaluer la "longueur" ou la "grandeur" d'un vecteur. La norme L1, également appelée norme absolue, quantifie cette longueur en additionnant simplement la valeur absolue de chacune des composantes du vecteur, sans élever ces valeurs au carré.
1.2. La formule clé
Pour un vecteur abstrait x = [x1, x2, ..., xn], la norme L1 s'écrit mathématiquement ainsi : ||x||1 = Σ |xi| = |x1| + |x2| + ... + |xn|
1.3. Origine du terme et espaces de Lebesgue
Contrairement à une idée reçue, la lettre "L" ne désigne pas une ligne ou un indice, mais fait référence au mathématicien français Henri Lebesgue. La norme L1 est un cas particulier (où p=1) de la famille générale des normes Lp définies sur les espaces de Lebesgue. Elle s'oppose à la norme L2 (p=2), qui est la distance euclidienne classique.
2. Exemple pratique de calcul
2.1. Calcul pas à pas
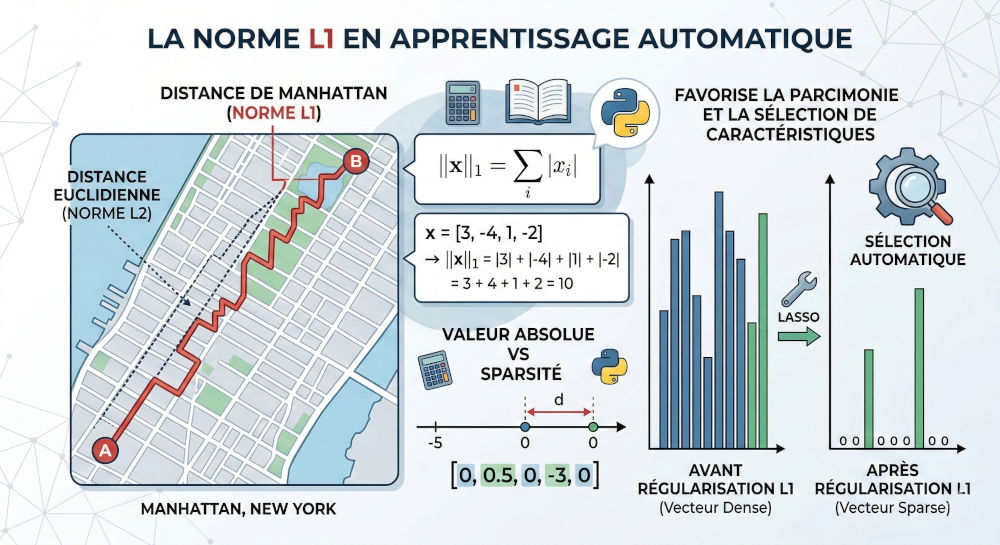
Prenons un vecteur concret dans un espace à 4 dimensions : x = [3, -4, 1, -2]. Le calcul de sa norme L1 consiste à ignorer les signes négatifs : ||x||1 = |3| + |-4| + |1| + |-2| = 3 + 4 + 1 + 2 = 10.
2.2. Décryptage de la notation
Dans la formule Σ |xi|, le symbole Sigma (Σ) indique une somme. L'indice i représente la position de la composante dans le vecteur (de la 1ère à la n-ième). Les barres verticales | | appliquent la valeur absolue, transformant tout nombre négatif en son équivalent positif.
2.3. Interprétation de la grandeur
Le résultat "10" représente le coût total ou l'effort global nécessaire pour parcourir chaque dimension l'une après l'autre. C'est une mesure de magnitude très robuste, car contrairement à la norme L2, elle ne pénalise pas excessivement les grandes valeurs (les valeurs aberrantes ou outliers), puisqu'il n'y a pas d'élévation au carré.
3. Implémentation Python : du code à la pratique
3.1. Méthode avec NumPy (recommandée)
import numpy as np
x = np.array([3, -4, 1, -2])
norme_L1 = np.sum(np.abs(x))
print(norme_L1) # Sortie: 103.2. Décorticage des fonctions
L'utilisation de NumPy est optimale pour les calculs vectoriels. La fonction np.abs(x) traite le tableau entier pour renvoyer [3, 4, 1, 2]. Ensuite, np.sum() agglomère ces valeurs. Ces opérations vectorisées sont écrites en C sous le capot, offrant des performances maximales.
3.3. Alternative native sans bibliothèque
x = [3, -4, 1, -2]
norme_L1 = sum(abs(xi) for xi in x)
print(norme_L1) # Sortie: 10Cette approche utilise une compréhension de générateur native à Python. Elle est excellente pour les petits scripts ou pour éviter d'importer NumPy, mais elle devient rapidement inefficace sur des vecteurs contenant des millions de données.
4. La géométrie de la norme L1 et la sparsité
La propriété la plus fascinante de la norme L1 est sa capacité à créer de la sparsité (ou parcimonie). Géométriquement, si l'on dessine l'ensemble des points ayant une norme L1 égale à 1 dans un plan 2D, on obtient un losange pointu aligné sur les axes, contrairement au cercle parfait de la norme L2. Lors de l'entraînement d'un algorithme d'optimisation, la solution a une très forte probabilité de "taper" dans un des coins pointus de ce losange. Or, ces coins se situent exactement sur les axes, ce qui signifie qu'une ou plusieurs composantes du vecteur deviennent rigoureusement égales à zéro. Un vecteur comme v = [0, 0.5, 0, -3, 0] est dit "sparse" car la majorité de ses valeurs sont nulles.
5. Pourquoi "norme de Manhattan" ?
5.1. L'analogie de la grille urbaine
Le surnom de cette norme provient de la topographie très spécifique de l'île de Manhattan à New York, où les rues (Streets) et les avenues (Avenues) se croisent à angle droit, formant un quadrillage parfait.
5.2. Déplacement contraint sans diagonale
Si un taxi veut se rendre d'une intersection A à une intersection B, il ne peut pas traverser les immeubles en diagonale (ce qui serait la distance euclidienne L2). Il est obligé de rouler vers le Nord/Sud, puis vers l'Est/Ouest.
5.3. Une distance additive pragmatique
La distance réellement parcourue par le taxi au compteur est exactement la somme de la distance horizontale et de la distance verticale. C'est l'illustration physique parfaite de la formule de la norme L1 : on additionne les écarts absolus sur chaque axe.
6. Applications en Machine Learning
6.1. La régularisation Lasso
L'application reine de la norme L1 en intelligence artificielle est la régularisation LASSO (Least Absolute Shrinkage and Selection Operator). En ajoutant la norme L1 des poids d'un modèle à sa fonction d'erreur, on force le modèle à "payer" pour chaque poids non nul qu'il utilise.
6.2. Sélection automatique de caractéristiques
Grâce à la géométrie en losange expliquée précédemment, l'algorithme Lasso va naturellement écraser les poids des variables les moins utiles jusqu'à exactement zéro. La norme L1 agit donc comme un outil mathématique de sélection de features (caractéristiques) totalement automatisé.
6.3. Les avantages de la parcimonie
Générer des vecteurs de poids sparses (parcimonieux) présente trois atouts majeurs : cela réduit drastiquement la taille du modèle en mémoire, cela accélère les prédictions en production, et surtout, cela simplifie l'analyse humaine en isolant uniquement les signaux importants du bruit.
7. Cas d'usage : un modèle prédictif épuré
7.1. Le problème des variables superflues
Imaginons un algorithme chargé de prédire le prix d'un appartement. On lui fournit 100 informations : la surface, le quartier, mais aussi l'âge du vendeur, la couleur de la porte ou le nombre de lettres dans le nom de la rue. Un modèle classique tentera d'attribuer une petite importance mathématique à chaque détail.
7.2. L'action du filtre L1
En appliquant une pénalité L1 (Lasso) lors de l'entraînement, le modèle est contraint d'être économe. La géométrie de la norme L1 va forcer les coefficients associés à "l'âge du vendeur" et "la couleur de la porte" à tomber à 0 absolu, car ils n'apportent pas assez d'information pour justifier leur "coût" dans la norme L1.
7.3. Un modèle final interprétable
À la fin du processus, le vecteur des poids du modèle sera sparse : seules 4 ou 5 variables (comme la surface et le quartier) auront une valeur non nulle. Le data scientist obtient ainsi un modèle extrêmement robuste, compréhensible par un humain, et immunisé contre le surapprentissage (overfitting).
8. En résumé
À retenir: La norme L1 (ou distance de Manhattan) est la somme des valeurs absolues d'un vecteur. En Machine Learning, son utilisation via la régularisation Lasso est un formidable levier pour forcer la sparsité. En poussant les coefficients inutiles à zéro, elle sélectionne automatiquement les variables pertinentes et rend les algorithmes plus légers et plus interprétables.